
„Werden meine Daten zum Training verwendet?“ – „Was passiert mit vertraulichen Kursinhalten?“ – „Kann ich das hier wirklich eingeben?“ Diese Fragen tauchen in praktisch jedem unserer Kurs auf, sobald KI-Tools im Spiel sind. Und das zu Recht, denn Einstellungen zum Datenschutz sind gut versteckt und die Standardkonfigurationen selten datenschutzfreundlich. In diesem Beitrag zeigen wir euch Schritt für Schritt, wie ihr die Kontrolle über eure Daten zurückgewinnt.
Weiterlesen: #kidi_11: So schützt ihr eure Daten bei ChatGPT & Co.In #kidi_09 hat Stefan bereits einen Überblick über KI-Funktionen gegeben – darunter auch erste Datenschutz-Tipps und DSGVO-konforme Alternativen zu gängigen KI-Modellen.
In diesem Beitrag erfahrt ihr…
- warum KI-Anbieter eure Eingaben standardmäßig zum Training nutzen – und was das konkret bedeutet,
- wie ihr bei ChatGPT & Co das Training mit euren Daten deaktiviert,
- was ihr keinesfalls in KI-Tools eingeben solltet,
- wann die Funktion „Temporärer Chat“ sinnvoll ist und
- was hinter den Daumen-hoch/Daumen-runter-Symbolen steckt.
1. Warum Trainingsdaten ein Risiko sein können
KI-Modelle wie ChatGPT, Gemini oder Claude werden kontinuierlich durch das sogenannte „Reinforcement Learning from Human Feedback“ (RLHF) verbessert. Das bedeutet, eure Eingaben können dazu verwendet werden, die KI „schlauer“ zu machen.
Das Problem dabei: Forschungsergebnisse zeigen, dass Sprachmodelle spezifische Sequenzen aus ihren Trainingsdaten speichern und unter bestimmten Bedingungen wieder ausgeben können. Dies schließt personenbezogene Informationen oder vertrauliche Inhalte ein.

Beispiel: Samsung-Leak von 2023
Der Samsung-Leak gilt heute als Paradebeispiel für unbedachte Datenpreisgabe. Samsung-Mitarbeitende haben vertrauliche Unternehmensdaten und Quellcode in ChatGPT eingegeben. Was sie nicht bedacht haben: Ihre Eingaben wurden auf externen Servern gespeichert und sind potenziell in das Training von ChatGPT eingeflossen.

Beispiel: Fotos im Stil von Ghibli
Im März 2025 führte OpenAI eine neue Bildgenerierungsfunktion ein, mit der Nutzer:innen Fotos im Stil des japanischen Animationsstudios Ghibli umwandeln konnten. Der virale Trend führte dazu, dass massenhaft persönliche Fotos hochgeladen wurden. Oft ohne Einwilligung der abgebildeten Personen.
Was wir gutgläubig zur Optimierung unserer Arbeit oder als Spielerei eingeben, kann ungewollt zu Datenschutzverletzungen führen. Insbesondere dann, wenn wir die Standardeinstellungen nicht anpassen.
2. Wie deaktiviere ich die Trainingsdaten?
Die Einstellungen dazu verstecken sich meist hinter irreführenden Bezeichnungen wie „Das Modell für alle verbessern“, wie hier bei ChatGPT:
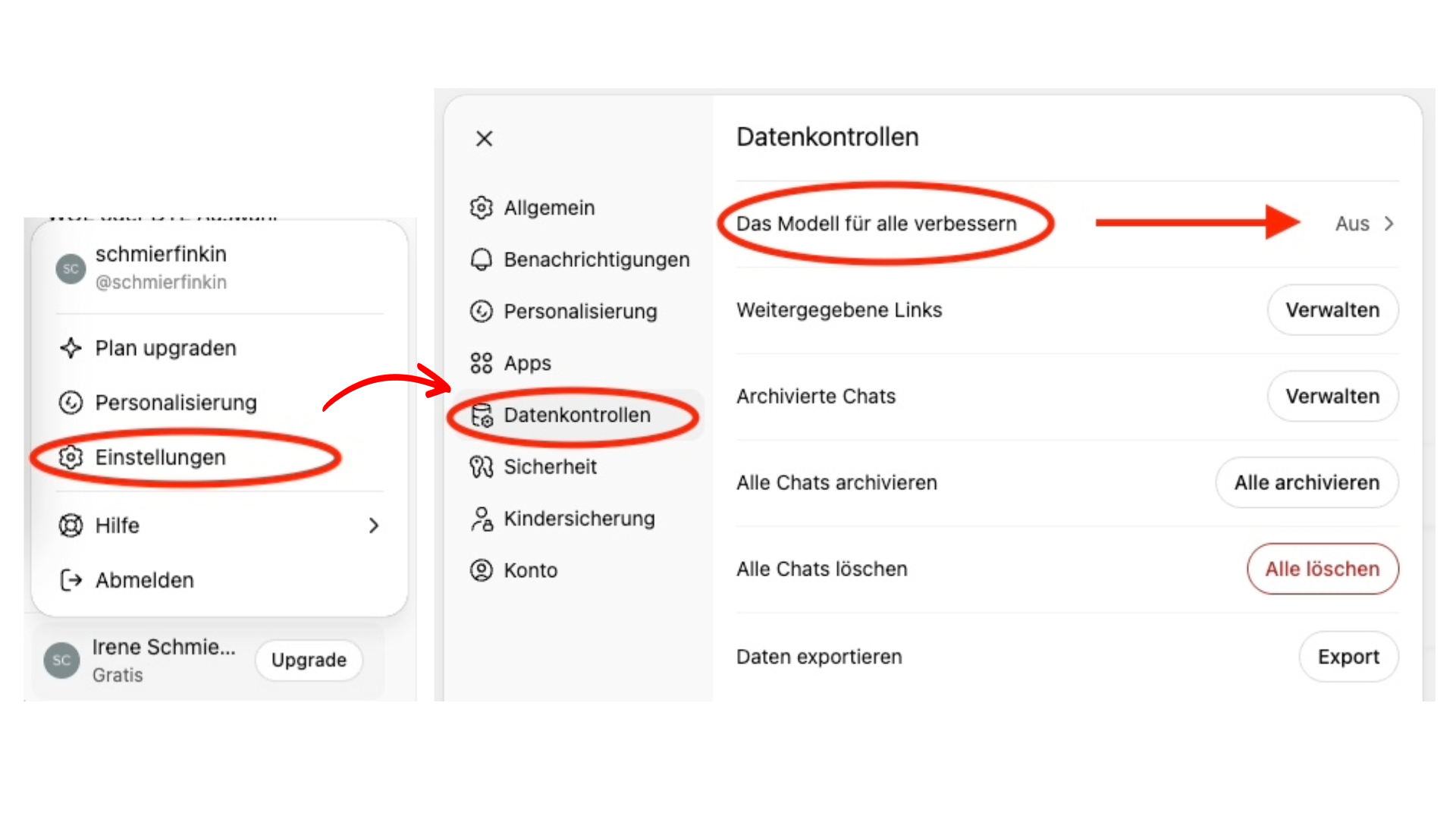
- Meldet euch bei eurem ChatGPT-Konto an.
- Klickt auf euer Profilbild (unten links oder oben rechts).
- Wählt „Einstellungen“ aus dem Dropdown-Menü.
- Navigiert zum Abschnitt „Datenkontrollen“.
- Deaktiviert den Schalter „Das Modell für alle verbessern“.
Wichtig: Diese Einstellung gilt nur für zukünftige Chats. Bereits geführte Gespräche könnten bereits für Trainingszwecke genutzt worden sein.
3. Welche Infos sollte ich besser nicht in ein KI-Tool eingeben?
❌ Personenbezogene Daten (Namen, Kontaktdaten, Geburtsdaten)
❌ Vertrauliche Kursmaterialien mit geschützten oder urheberrechtlich sensiblen Inhalten
❌ Interne Dokumente eurer Organisation (Strategiepapiere, Finanzpläne, Sitzungsprotokolle)
❌ Informationen über Kund:innen oder Geschäftsbeziehungen
❌ Passwörter, Zugangsdaten, Kontoinformationen
❌ Medizinische, psychologische oder besonders sensible persönliche Informationen
❌ Vollständige E-Mails oder Protokolle mit Personenbezug (außer vollständig anonymisiert)
Faustregel: Würdet ihr diese Information auf eine Pinnwand im Büro hängen, wo jede:r sie lesen kann? Nein? Dann gehört sie auch nicht in die KI.
Diese Grundregel gilt unabhängig davon, welche Datenschutzeinstellungen ihr vornehmt. Denn selbst bei deaktiviertem Training werden eure Daten temporär gespeichert – und im Fall von Sicherheitsprüfungen oder rechtlichen Anforderungen können sie durchaus eingesehen werden.
4. Was ist der „temporäre Chat“ und wann ist er sinnvoll?
Auch wenn ihr das Training deaktiviert habt, werden eure Chats in der Regel gespeichert und erscheinen in eurer Historie. Für besonders sensible Anfragen – etwa wenn ihr vertrauliche Dokumente analysieren oder persönliche Situationen besprechen wollt – gibt es eine zusätzliche Schutzebene: den temporären Chat.
Der temporäre Chat funktioniert ähnlich wie der Inkognito-Modus eines Webbrowsers. Die Konversation wird weder in eurer Historie gespeichert noch für die Personalisierung künftiger Antworten verwendet. Nach einer bestimmten Zeit (meist 30 Tage) wird der Chat endgültig gelöscht.
So aktiviert ihr den Modus:
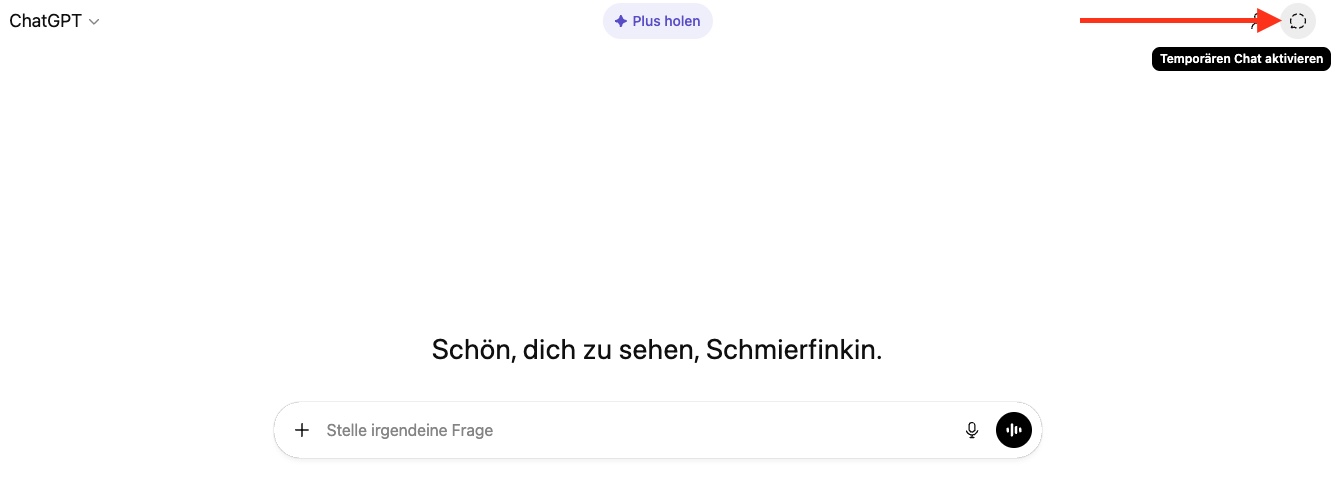
Bei ChatGPT: Klickt auf das Symbol für „Temporärer Chat“ oben rechts neben eurem Profilbild. Der Bildschirm wird dunkler, um zu signalisieren, dass ihr euch im temporären Modus befindet.
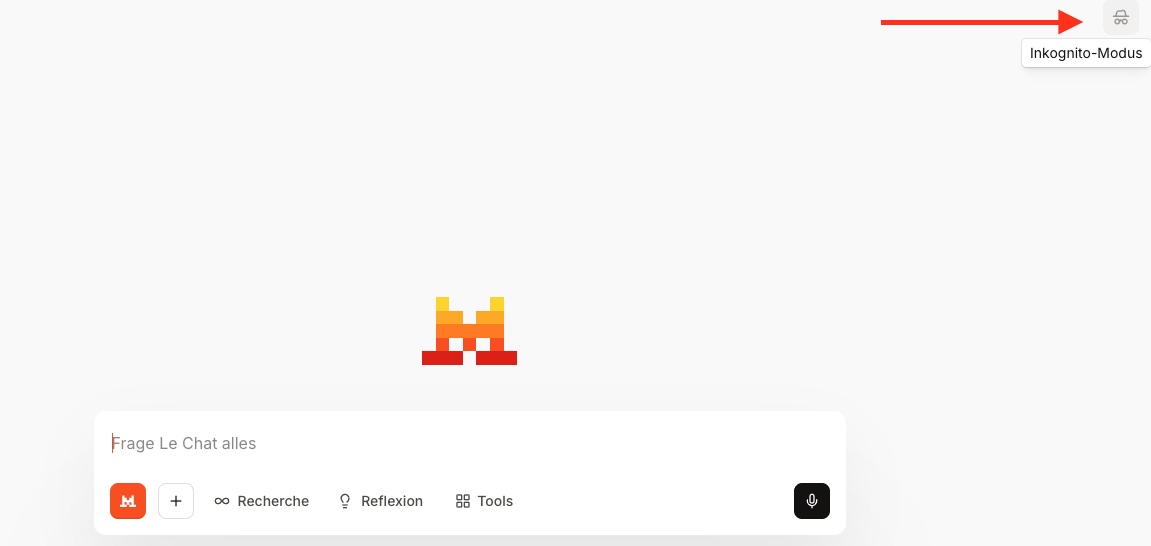
Auch bei anderen KI-Sprachmodellen findet ihr den temporären Chat rechts oben, meist als „Inkognito-Modus“:
| Vorteile des temporären Chats | Nachteile des temporären Chats |
| ✅ Minimiert den digitalen Fußabdruck auf den Servern des Anbieters | ❌ Kein Zugriff auf frühere Konversationen für Referenzzwecke |
| ✅ Verhindert, dass die KI Informationen in den Langzeitspeicher übernimmt | ❌ Die KI „vergisst“ den Kontext sofort nach Beendigung der Sitzung |
| ✅ Reduziert das Risiko, dass bei einem möglichen Kontozugriff durch Dritte Chatprotokolle eingesehen werden können | ❌ Schützt nicht vor Echtzeit-Überwachung auf dem lokalen Endgerät |
Wichtig: Auch im temporären Modus sind die Daten nicht „unsichtbar“ für den Anbieter. Sie werden in der Regel für 30 Tage vorgehalten, um Missbrauch zu identifizieren und rechtliche Anforderungen zu erfüllen.
5. 👍 👎 Daumen hoch, Daumen runter: Was steckt hinter den Symbolen?
Die Symbole für „Daumen hoch“ und „Daumen runter“ unter den KI-Antworten wirken wie harmlose Zufriedenheitsabfragen. Tatsächlich sind sie aber aktive Eingaben in den Prozess des Reinforcement Learning from Human Feedback (RLHF).

Was passiert, wenn ihr Feedback gebt?
Wenn ihr auf eines der Symbole klickt, sendet ihr nicht nur eine einfache Bewertung, sondern meist auch den gesamten Gesprächskontext zur Analyse an den Anbieter. Insbesondere negatives Feedback wird oft von menschlichen Trainer:innen gesichtet, um Fehlerquellen zu identifizieren.
Das bedeutet konkret: Die betreffende Konversation kann – ungeachtet sonstiger Datenschutzeinstellungen – von einer realen Person gelesen werden. Bei Anthropic werden solche Feedback-Daten bis zu fünf Jahre aufbewahrt.
| Vorteile von Feedback | Nachteile von Feedback |
| ✅ Verbesserung der faktischen Korrektheit der KI | ❌ Erhöhte Datenexposition durch menschliche Überprüfung |
| ✅ Reduzierung von Bias und problematischen Inhalten | ❌ Längere Aufbewahrungsfristen (bei Anthropic bis zu fünf Jahre) |
| ✅ Optimierung der Sicherheitsfilter | ❌ Mögliche Einsicht in sensible Gesprächsinhalte |
Empfehlung: Gebt Feedback nur dann, wenn die Konversation keine sensiblen oder persönlichen Daten enthält. Bei vertraulichen Anfragen solltet ihr auf die Feedback-Funktion verzichten.
Praktische Empfehlungen für den Bildungsalltag
- Training deaktivieren: Unmittelbar nach der Registrierung solltet ihr das Training in den Einstellungen ausschalten.
- Temporären Chat einrichten: Macht euch mit dem temporären Chat-Modus vertraut und nutzt ihn für sensible Anfragen.
- Vorsicht bei Feedback: Gebt kein Feedback (Daumen hoch/runter) zu Chats, die vertrauliche Informationen enthalten.
- Datenschutzbestimmungen lesen: Nehmt euch die Zeit, die Datenschutzbestimmungen der einzelnen Tools durchzulesen – sie ändern sich regelmäßig.
Autorin: Irene Steindl
Lust auf mehr? Zu allen Beiträgen der Serie kommst du HIER!


Dieses Werk ist lizenziert unter einer Creative Commons Namensnennung-NichtKommerziell-Weitergabe unter gleichen Bedingungen unter gleichen Bedingungen 3.0 Österreich Lizenz.
Volltext der Lizenz
Ich würde ein in Deutschland gehostetes LLM verwenden wenn es online erreichbar sein soll. Lokale Hardware für AI liegt bei ca 1.000 Euro damit sie funktionieren.
Lieber Fred, danke für deinen Hinweis.
Liebe Grüße
Dein REFAK-Team